[Errors], [Pipes], [FIFOs], [Socketpairs], [Protection], [File Locking], [SystemV Semaphores], [Shared Memory], [Memory Mapped IO], [Sendfile]
ECHILD : No children EINTR : Interrupted system call <-- This is very important EINVAL : Invalid argument EPIPE : Broken pipeBeware that errno is updated only when a call fails, not after each call!
We can use the Standard C Library function strerror to return a string describing the meaning of the current value of errno.
#include <string.h> char *strerror(int errnum);For example:
fprintf(STDERR_FILENO, "In Child 1: %s\n", strerror(errno));
We can use the Standard C Library function perror to write to the standard error file a string of our chosing and a description of the errno value.
#include <stdio.h> void perror(const char *string);For example:
perror("In Child 1");
#include <unistd.h>
int pipe(int filedescriptor[2]);
It returns 0 for success and -1 for failure
When successful it places two file descriptors in filedescriptor,
one at 0 for reading, one at 1 for writing. These two
files are the endpoints of a pipe. [In some systems both
ends of a pipe are bidirectional.]
The capacity of a pipe in bytes is usually defined by the
constant PIPE_BUF. One may write to a pipe a block that is
larger than PIPE_BUF, but in that case the write operation
is not guaranteed to be atomic [i.e. concurrent writes may
interleave their data] [PIPE-BUF is something like 512, POSIX,
or 4096, Linux].
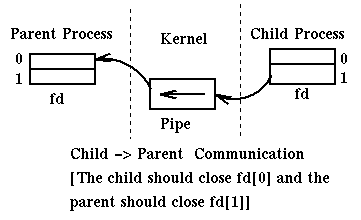
Usually pipes are opened by a process which then forks. Then the parent process and the children processes can communicate through the pipe. For example:
Here is a complex way of writing our favorite program "Hello World" and here is an implementation of the shell command:
uncompress filename | tar -xfv -and here is, using a different method, the implementation of
cat filename | grep token
If we try to write to a pipe whose reading end has been closed we get a SIGPIPE signal. If we try to read from a pipe whose writing end has been closed, read returns 0.
A useful implicit use of pipes is in the C standard library functions:
#include <stdio.h>
FILE *popen(const char *cmdstring, const char *type);
It executes cmdstring and returns a file.
We read from that file the output of the command, if type is "r"
We write to that file the input for the command, if type is "w"
int pclose(FILE *fp);
and here is a simple use of popen:
#include <stdio.h>
#define MAXSIZE 256
int main(int argc, char **argv)
{
char line[MAXSIZE];
FILE *fp;
if ((fp = popen("ls","r")) == NULL) {
perror("popen error");
exit(1);
}
while (fgets(line, MAXSIZE, fp) != NULL) {
printf("%s",line);
}
pclose(fp);
return (0);
}
The program executes an "ls" command, captures its output, and displays
it to the screen. Of course we could have achieved the same effect,
in this case, with the simpler command system.
Consider a really old software system, with text input and text output. Then we could interface to it using a program with a nice GUI. It is easy to do with two pipe operations, a fork, two dup2 calls, and an exec of the old software.
#include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *path, mode_t mode); where path is the name for the fifo amd mode specifies the access mode to the fifo.The following two programs twin1.c and twin2.c show how two distinct programs can communicate through a fifo in a Producer - Consumer fashon. The following programs, dtwin1.c and dtwin2.c, instead, show how two FIFOs can be used for bidirectional communication between two proceses.
#include <sys/socket.h>
int socketpair(
int domain,
int type,
int protocol,
int socket_vector[2] );
For our purposes the value of domain is AF_UNIX,
the value of type is SOCK_STREAM, the value of protocol is 0,
and socket_vector is the address of the array where we want to store
the socketpair's file descriptors.
The value returned by the call is 0 in case of success, -1 in
case of failure.
In socketpair.c the program creates a socketpair and then forks. The child redirects standard input and output to its end of the socketpair and then executes the program echoline.c that in a loop reads a line from standard input and writes it to standard output. The parent in a loop reads a line from standard input, writes it to its end of the socketpair, reads a line from its end of the socketpair, and prints it out to the standard output. A restriction on the use of socketpairs as intermediary between interacting processes is that we cannot use on them Standard C functions like fprints and fscanf. We are restricted to the use of Unix functions such as read and write. Pseudo-terminals allow the use of the Standard C functions, but we are not reviewing that topic [see Stevens]. Even better than socketpairs are sockets in the Unix domain, which we will discuss in the discussion of the client-server architecture.
Unix recognizes the following User Kinds: ogua [o: owner;
g: group; u: user; a: all of the above] and the following
Operation Rights: rwxst [r: Read access; w: Write access;
x: Execute access; s: Set_user_id;
s: Set_group_id; t: text;]
The set-user-id, set-group-id are particularly interesting (and protected by
patent) because they allow a process to execute a file with the rights
of the owner of the file and not of the owner of the process (why is this so
nice?.)
The 9 protection bits of a file (3 groups of 3: rwx. From left, 3 for user, 3 for group, and 3 for others)
are usually represented as an octal number. For example 744 means that the user (7 = rwx) has all rights,
and group and other can only read (4 = r--).
Beware that operation rights can have different meaning on directories and on
regular files. Review the shell command chmod and the shell command umask
(or the Unix system call umask). When we create a file, its protection bits
will be the bit-and of the bits specified in the mode of the open call
and the bit-complement of the current umask. So if the current umask is 27
(octal 27), and the creation mode is 744 then the file created will will have
the protection bits 740.
File locking can be file oriented or
record oriented depending on the
scope of the lock, the whole file or a portion thereof.
When a lock is applied, it can be a read lock (i.e. multiple concurrent
read locks are allowed, but no write locks)
or a write lock (i.e. exclusive with all locks).
Locking can be
mandatory or advisory. Advisory locks have effect only for
processes that follow the protocol :
lock a file before accessing it and unlock it after.
Mandatory locks protect a file also against processes that
do not use the lock/unlock protocol.
Mandatory locks should be avoided
whenever possible because of efficiency reasons.
Locks can be blocking or non blocking. They are blocking if
when a lock cannot be immediately acquired the process executing the call
waits; it is non-blocking if the call returns with a code that indicates
success or failure in acquiring the lock.
A basic commands for locking files is fcntl which uses the data structure flock.
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
int fcntl(int filedes, int cmd, struct flock *flockptr);
cmd can be F_GETLK (get lock information into flockptr structure),
F_SETLK (create lock according to info in flockptr structure
and do not block if the lock cannot be created immediately),
F_SETLKW (same as F_SETLK, but now blocking)
fcntl return -1 in case of error, a non-negative number otherwise.
struct flock{
short l_type; /* This field can take the values:
* F_RDLCK - read (shared) lock
* F_WRLCK - write (exclusive) lock
* F_UNLCK - remove lock(s)
*/
off_t l_start; /* offset in bytes to beginning of record being locked*/
/* starting from position specified by l_whence */
short l_whence; /* This field can take the values:
* SEEK_SET - offset is relative to beginning of file
* SEEK_CUR - offset is relative to cursor
* SEEK_END - offset is relative to end of file */
off_t l_len; /* length in bytes of record being locked */
pid_t l_pid;} /* pid of process owning the lock */
The information in flock is relative to the current process. Other
processes using this file will have their own flock structures.
Here is code, copied from Stevens, for using fcntl to set a read lock or a
write lock (both blocking and non blocking versions) and for unlocking a file:
#include <sys/types.h>
#include <fcntl.h>
int lock_reg(int fd, int cmd, int type, off_t offset, int whence, off_t len)
{
struct flock lock;
lock.l_type = type;
lock.l_start = offset;
lock.l_whence = whence;
lock.l_len = len;
return (fcntl(fd,cmd,&lock));
}
#define read_lock(fd, offset, whence, len) \
lock_reg(fd, F_SETLK, F_RDLCK, offset, whence, len)
#define readw_lock(fd, offset, whence, len) \
lock_reg(fd, F_SETLKW, F_RDLCK, offset, whence, len)
#define write_lock(fd, offset, whence, len) \
lock_reg(fd, F_SETLK, F_WRLCK, offset, whence, len)
#define writew_lock(fd, offset, whence, len) \
lock_reg(fd, F_SETLKW, F_WRLCK, offset, whence, len)
#define un_lock(fd, offset, whence, len) \
lock_reg(fd, F_SETLK, F_UNLCK, offset, whence, len)
Here is how we can use a file lock to implement a critical region (We assume we have the definitions for writew_lock and un_lock.)
#define FILE_MODE (S_IRUSR | S_IRGRP | S_IROTH | S_IWUSR)
/* permissions for new files: Read permission for
* user, group, and others; write permission for owner. */
int main(void)
{
int fd;
if ((fd = open("lockfile", O_WRONLY | O_CREAT, FILE_MODE)) < 0) {
perror ("open error");
exit(1);}
if (writew_lock(fd,0,SEEK_SET,1) < 0) { /* prolog */
perror ("lock error");
exit(1);}
sleep(30); /* this represents the critical region */
un_lock(fd,0,SEEK_SET,1); /* epilog */
exit(0);
}
[If you compile this program, say into a.out, and then execute at the
shell prompt
a.out&; a.out&; a.out&
you will see the background jobs terminate at 30 second intervals.]
Stevens shows that advisory file record locking can be used in place of semaphores to implement critical regions essentially without any performance degradation.
There is also a function flock which is easier to use than fcntl. It works with advisory locks. However, while fcntl works even in a distributed file system (see example), flock works only on processes sharing the same computer (at least it is so on OSF on my alpha).
Here is a simple use of flock to implement a critical region:
#include <sys/file.h>
int main(void){
int fd;
if ((fd = open("lockfile", O_WRONLY | O_CREAT)) < 0) {
perror ("open error");
exit(1);}
flock(fd, LOCK_EX); /* prolog */
sleep(30); /* this represents the critical region */
flock(fd, LOCK_UN); /* epilog */
exit(0);
}
For portability it is recommended to avoid flock.
You can look at another way of using file locks in the hints for an old homework.
Shared memory segments are an example of IPC resources (other examples in Unix are semaphores and named queues). In Unix these resources are associated to identifiers, i.e. to unique names (unique at an instant since identifiers may be reused). We need to make sure that communicating processes all know the identity of the shared IPC. This can be done by agreeing on a key (a string) to be converted to an identifier by the system (but nobody guaranties uniqueness of keys) or by passing the identifiers at run time in some fashion among the communicating processes.
When using IPC resources in Unix it is important to make sure that these resources are deleted after use and do not remain in the system. You can make sure that things are ok by using the shell command ipcs to determine which resources are in use and the command ipcrm to remove those you own and want removed.
Here are the basic functions and constants for using shared memory:
SHMLBA means 'low boundary address multiple'. It is a power of 2.
It represents the required alignment for the shared segment.
SHM_R and SHM_W are flag for read and write permission.
SHM_LOCK and SHM_UNLOCK specify 'Lock segment in core' and
'Unlock segment from core'.
#include <sys/shm.h>
int shmget (key_t key, int size, int flag);
get shared memory segment identifier.
Returns the shared memory identifier associated with KEY,
or -1 in case of error.
A shared memory identifier and associated data structure and
shared memory segment of at least size are created for KEY if one
of the following are true:
key is equal to IPC_PRIVATE, or
key does not already have a shared memory identifier
associated with it and IPC_CREAT is specified in flag, or
key has already a shared memory identifier associated
with it and IPC_CREAT is specified in flag and IPC_EXCL
is not specified in flag.
We will only use the IPC_PRIVATE form, in which case the shared memory
segment can be used only in children of the creator process.
flag is the or of flags like IPC_CREAT (create a new segment), IPC_EXCL
(fail if the segment exists already), and mode (the usual protection flags).
Upon creation, the data structure associated with the new
shared memory identifier is initialized.
The way we use it, the shmget command should be executed
by exactly one of the processes sharing the memory segment.
int shmctl (int shmid, int cmd, struct shmid_ds *buf);
It is used to examine or update the characteristics of an
existing segment.
Returns 0 if ok, -1 on error
cmd parameter is:
IPC_STAT Fetch shmid_ds for this segment and store its value at buf
IPC_SET Set shm_perm.uid, shm_perm.gid, shm_perm.mode
from buf. Can be executed only by shm_perm.cuid, or
shm_perm.uid, or superuser.
IPC_RMID Remove shared memory segment from system.
[It reduces count of users. When 0, it is deleted.]
It can be executed only by shm_perm.cuid,
or shm_perm.uid, or superuser.
SHM_LOCK Lock segment in memory. Only the superuser.
SHM_UNLOCK Unlock segment from memory. Only the superuser.
Here is the definition of struct shmid_ds:
struct shmid_ds{
struct ipc_perm shm_perm; /*Protection inof for this region*/
int shm_segsz; /*Size of shared region in bytes*/
u_short shm_lpid; /*Process Id of creator of this region*/
u_short shm_cpid; /*Id of last process to perform shmat or shmdt
on this region*/
u_short shm_nattch; /*Number of processes currently attached*/
time_t shm_atime; /*Time of last shmat operation*/
time_t shm_dtime; /*Time of last shmdt operation*/
time_t shm_ctyme; /*Time of last shmctl operation*/
}
void *shmat(int shmid, void *addr, int flag);
It is used to bind an address in the process space to the origin
of a shared segment.
Returns pointer to shared memory segment if ok, -1 on error.
If addr is 0, the segment is attached at the first available
address (in the user space) as selected by the kernel. Best way.
If addr<>0 and SHM_RND is not specified in the flag,
the segment is attached at the address given by addr.
If addr<>0 and SHM_RND is specified in the flag,
the segment is attached at the address given by
(addr - (addr mod SHMLBA)).
If flag contains SHM_RDONLY, then the segment can only be read
not written to.
int shmdt(void *addr);
Detaches this segment from the process's address space.
The segment is not removed from system until the segment
is actually removed by using shmctl.
Here is an example of use of shared memory. A process forks.
The child will ask interactively an integer from the user, store it
in shared memory, and then terminate.
The parent will wait for the child to terminate,
read the integer from shared memory and print it out.
It is all fairly easy since the identity of the shared segment as created
by the parent is inherited by the child.
You can check from another terminal with ipcs that:
Since we now have a way of sharing physical memory between Unix processes, it becomes fairly easy if one so desires to implement spinlocks, semaphores, and monitors among Unix processes.
Memory Mapped IO commands allow us to map files to memory and then to use the in memory structures just as any other memory structure, and to see any change we make to this memory structure reflected in the file. The file, and the corresponding memory, can be shared between multiple processes. Some form of lock must be used to enforce desired mutual exclusion. We can control the extent by which the values in the process memory and in the file are consistent.
#include <sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int flags,
int fd, off_t offset);
addr is usually 0, asking the system to map the file to
the address it prefers.
len is the number of bytes that are mapped to the file.
fd must be the file descriptor of the open file we want to map
to memory.
offset is usually 0, it represents the first byte of the file that
is mapped to memory. All locations in the file, from
position offset, to position offset+len-1, must be already
allocated to the file (or you will have a bus error).
[See below the file copy program by Stevens for a way
to do this.]
prot indicates what we can do with the mapped area. We will
use PROT_READ | PROT_WRITE if we want to read and write,
and just PROT_READ if we want only to read. (There is
also PROT_EXEC and PROT_NONE.)
flags indicate properties of the mapped region. Flag values
indicate if the changes that are made to the memory
structure will be private to only this process or they
will be reflected in the file and seen by concurrent
processes. The possible values are MAP_PRIVATE (changes
made in main memory do not modify the file) and
MAP_SHARED (changes in main memory modify the file).
Even when the flag is MAP_SHARED it is not true that
the file has at all times the same value as main memory
(see msync below). We usually use MAP_SHARED. The flag
MAP_FIXED is to indicate that we require addr to be used
as the start address of the mapped region.
The function returns the address where the mapped area begins,
or it returns MAP_FAILED if it did not succeed.
int munmap(void *addr, size_t len);
It terminates the association between memory structure and file that
was established by mmap. It updates the file's content if the
area was MAP_SHARED.
addr is the value returned by mmap.
len is the len parameter used in the mmap command (or smaller).
int msync(void *addr, size_t len, int flags);
It synchronizes the memory data with the file content.
addr is the value returned by mmap.
len is the len parameter used in the mmap command (or smaller).
flags is either MS_SYNC, MS_ASYNC, or MS_INVALIDATE. If flags
is MS_SYNC, the file is made equal to the memory value.
If it is MS_ASYNC, the write operation is asynchronous (i.e.
just queued). If it is MS_INVALIDATE, all in memory contents
that are inconsistent with the file are invalidated and
will require (implicit) re-reading.
The fact that we can share memory between processes and automatically back
the information of that memory into a file, allows us to build systems that
have persistent storage and can withstand many hardware and power failures.
The following
program from Stevens uses memory mapped IO for
copying files.
We are given a file containing the social
security, name, and grade of students. All fields are fixed sized
character data terminated by one blank.
We can replace these terminators with '\0' using the following
program.
In turn we can print out the content of
the file with the following program.
The following program compares the time required
to compute the checksum of a file
using the traditional read etc. operations, and the time required if the
file is memory mapped.
Here are the results, using files of different sizes and 10 iterations at
each size
MAP | I/O
==================================|=============================
SIZE MIN AVG MAX | MIN AVG MAX
512 0 1.20 12 | 0 0.10 1
2048 0 0.90 5 | 0 0.40 1
8192 0 1.90 11 | 3 3.10 4
32768 5 7.20 24 | 13 14.20 16
131072 21 27.20 62 | 56 59.60 62
524288 88 96.30 143 | 236 238.60 241
2097152 362 376.10 478 | 953 971.20 1053
As you can see, for files that are 8KB or more, the performance of memory
mapped files is far superior.
There is a way to use mmap in conjunction with the file /dev/zero to share memory between processes. [By the way, Unix has 3 convenint files, /dev/null, /dev/zero, and /dev/random you may want to read about.]
#includeThe sendfile call is executed in the kernel and it takes advantage of IO memory mapping facilities. Here we use sendfile to copy a file. In the future we will see how to use sendfile when implementing a web server. ingargio@joda.cis.temple.edussize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);